Applying CBM and PHM concepts with reliability approach for Blowout Preventer (BOP): a literature review
Filipe Brandão Martins
fmartins@qgog.com.br; filipeb.martins@hotmail.com
Queiroz Galvão Oil and Gas, Rio das Ostras, Rio de Janeiro, Brazil.
Rodolfo Cardoso
rodolfo.cardoso@lei.uff.br
Fluminense Federal University, Rio das Ostras, Rio de Janeiro, Brazil.
Iara Tammela
iaratammela@gmail.com; iaratammela@id.uff.br
Fluminense Federal University, Rio das Ostras, Rio de Janeiro, Brazil.
Danilo Colombo
colombo.danilo@petrobras.com.br
Petrobras, Rio de Janeiro, Rio de Janeiro, Brazil.
Bruno Acioli de Matos
b.acioli@subseaservices.no
Sub Sea Services AS, Stavanger, Norway.
Abstract
The sensibility originated by the Blowout Preventer (BOP) theme, due to all attention gathered after the Macondo event, established a high level of requirements from regulatory agencies, clients and Drilling Contractors themselves. Based on these pillars, the concept of reliability has been constantly applied in the oil industry, especially in the Well Safety and Control System, where it is extremely important for the equipment to be reliable and operational when required. In parallel, the Condition Based Maintenance (CBM) and Prognostic Health Management (PHM) concepts, widely used in critical industries, which require high reliability levels, are being pointed out as the future for the BOP system management. Within this context, the purpose of this paper is to review the literature on Condition Based Maintenance and Prognostic Health Management, integrated with reliability concepts, and to enable them to be applied in the BOP health management. The paper identifies different concepts needed to support the main theme and, through research and selection criteria, it brings together a set of publications to obtain consistent theoretical framework. This research outlines important techniques used in high reliability industries and the way they can be applied on the BOP system and it also provides many useful references and case studies to assist on further development works in terms of well control and operational safety.
Keywords: PHM; CBM; Condition Monitoring; FMMEA; BOP; Failure analysis; Reliability; RCM.
1 Introduction
Safety well drilling condition is the most important aspect to be considered during exploration and production of oil and gas. One of the biggest risks for operational safety is an uncontrolled influx of oil and gas from the formation to the surface, which means a blowout. In order to ensure the control and safety of the well, offshore rigs are equipped with a Blowout Preventer (BOP) that makes possible the controlling of hydrostatic pressure and allowing the well to shut in case of unbalanced situation (difference between the pressure of the mud column and the well pressure) (Martins et al., 2015).
As Sattler mentioned (2013, p. 1), “BOP equipment and systems have been understood as one of the most safety critical of all rig equipment. Although it is not the primary resource used by the driller for well control, they are correctly understood as one of the last line of defense”. Therefore, BOP is an important safety barrier during drilling operations and, when it is missing, is degraded, or has failed, it allows the initiating event to grow to a major accident with catastrophic consequences (Qing Feng et al., 2011; Nelson, 2016). Rausand et al. (1983), in his blowout study in 1980, highlighted that one of 125 exploration wells experienced a blowout event and 65% of blowouts occurred through the BOP, drill string or annulus and could have been avoid by using the BOP functions.
The primal example of a catastrophic blowout accident magnitude was the Macondo event, on April 20th 2010. One of the largest offshore oil spills ever in the US history was considered the biggest environmental catastrophe since then. It was approximately 4.9 million barrels of crude oil straight into the ocean. The blowout also killed 11 crew people, drillers of the Transocean rig, Deepwater Horizon (Klakegg, 2012; Saetre, 2015). Many investigations were conducted to understand the root cause of the accident. The US Chemical Safety Board (2010, p. 8) described that “the management system, intended to ensure the required functionality, availability, and reliability of these safety critical barriers, were inadequate”. It means that BOP, responsible to prevent and control a blowout, failed when it was triggered. Members of the Center for Catastrophic Risk Management - CCRM (2011, p. 5) concluded that the accident was the “result of a cascade of deeply flawed failure regarding decision-making, communication, and organizational-managerial processes”.
Besides being a safety problem, BOP failures and malfunctions are costly. When a failure in the BOP or its control system is detected, drilling operations must usually cease in order to repair the failure (Rausand et al., 1983), requiring pulling the risers and the BOP to the surface and for performing a corrective maintenance. Additionally, a lot of functional and pressure tests have to be done to guarantee the safety barriers during operations. Such round trip to repair the BOP would result in a cost of approximately US $1 million per event, turning into one of the most expensive downtime events (Shanks et al., 2003). Currently this cost can be more expensive, due to ultra-deep-water operations and the complexity of BOP with more preventers and backups, consequently, needing more time to test all the system and to pull and run the BOP. Alme et Huse (2013, p. 1) showed that “Some estimates put the cost as high as US $ 1.2 million a day and beyond”.
1.1 BOP reliability and condition monitoring approach
BOP reliability studies have been developed since 1980 and many reports have been published over the years, especially by Per Holand et Rausand (1983; 1986; 1987; 1989; 1997; 1999; 2001) in order to collect data and improve knowledge regarding reliability concepts. This study is important to establish a BOP reliability level in order to improve maintenance and risk analysis on decision making. Many challenges were encountered in implementing the BOP reliability approach, mainly to the lack of high quality failure data and standard taxonomic structure to obtain the components’ life traceability. Sandtorv (1996, p. 166) in OREDA project emphasized that data quality and availability varies significantly between companies and highlighted that, in order to have a clear definition process and specification, and data type and format, it is paramount to obtaining high quality data.
The implementation of reliability concepts is also important to develop the BOP condition monitoring. For establishing a prognostic health management, parameters can be determined based on the relationship between failure modes and mechanism and effect analysis (FMMEA). In addition, it provides guidelines for defining the major operational stresses and environmental and operational parameters (Cheng et al., 2010b).
Real-time monitoring technology is becoming more increasingly used on offshore drilling, as more capabilities for transmitting and storing a high volume and range data in order to enhance both safety and operational efficiency through more informed operational decision making. Nevertheless, the application of technology to bring intelligence for exploring this data is less mature, especially in predictive analytical areas, which could provide guidance for drilling teams to help on operation decision making (Harder et al., 2015; Israel et al., 2015).
According to Shin (2015, p. 120), “recently lots of manufacturing companies are trying to adopt new technologies and get more accurate real-time information regarding product status during its usage period. As diverse information becomes available, the CBM approach to use them for preventing a critical failure or degradation has been highlighted”.
Having a constant knowledge of the equipment’s condition, in complex and aggressive operation environment conditions, allows early proactive maintenance planning, hence reducing downtime and maximizing intervention efficiency (Hwang, 2015; Chze et al., 2016). Nonetheless, this is still far from the reality of BOP maintenance.
The Original Equipment Manufacturer (OEM) recommendations still have uncertain maintenance frequency criteria or were based on laboratory parameters. Such parameters do not present all the necessary operation and environmental conditions that affect the component’s life. In addition, there is a lack of studies to provide a detailed BOP’s FMMEA to provide an efficient analysis between failures and real-time monitoring parameters.
Considering the trends in the use of reliability concepts, the advance of real-time monitoring technology and the importance of BOP for drilling operations, this paper presents an extensive literature review on Condition Based Maintenance and Prognostic Health Management integrated with reliability concepts. The goal is to allow them to be applied in BOP health management, aiming to increase BOP reliability and availability and the operational safety of offshore rigs.
2 Methodology
This section provides a practical overview of the literature review methodology. Firstly, the central theme of this research was systematically subdivided into specific knowledge items and organized in a theoretical framework to increase the background for reaching the main goal. The knowledge areas identified in this study were: Failure analysis; reliability; BOP system and drilling operations; CBM and PHM concepts and process, as shown in Figure 1.
For this research purpose, a detailed literature search on each theme of theoretical framework was carried out. For each type of publication, a specific electronic data source was used, such as “Onepetro” for the conference papers. In addition, key words, relevant authors, paper’s references and journals were used as search methods to find all publications of this paper. Figure 2 shows an overview of search methodology.
Figure 1. Theoretical framework
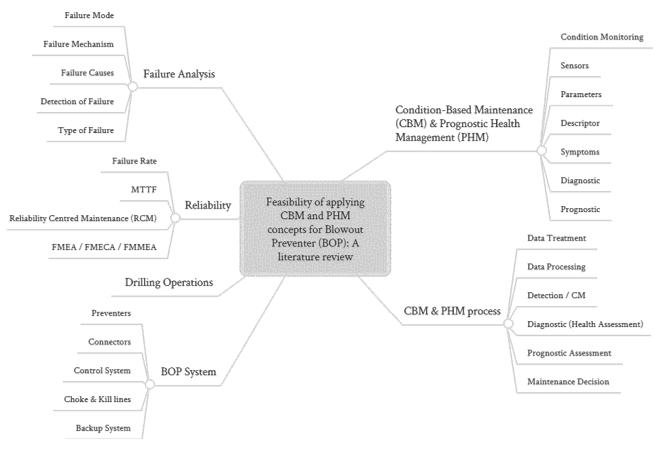
Source: The author(s)’ own (2017)
The selection criteria were adopted according to each type of publication, as detailed in table 1. Firstly, an impact factor, in which 60% were classified as “A”, was adopted for journals. For (co)author citation relevance were considered journals, books and theses, with 60% of over 1000 citations. The year of publication was also considered for journals, conferences and theses, in which 76% had less than 10 years. Finally, to evaluate the theses the University was analyzed, in which Norwegian University of Science and Technology reached 62%, since it has an extensive research group in BOP Safety and BOP reliability area.
Figure 2. Search methodology overview
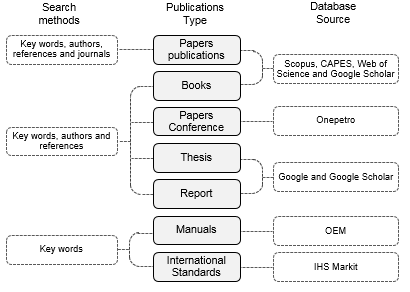
Source: The author(s)’ own (2017)
Table 1. Criteria
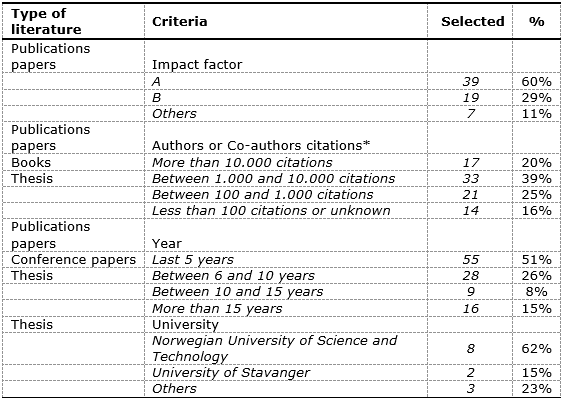
Source: The author(s)’ own (2017)
All publications were reviewed and the ones not considered relevant, outdated, with poor quality or unknown source were excluded, through the selection criterion adopted. Because of the literature search, papers published in the following journals, standards, books, reports, manuals, conferences papers and thesis were shortly listed for this review and shown in Table 2. A total of 197 publications were selected. Most of these journals and publications appeared in Reliability Engineering and System Safety and Journal of Quality in Maintenance Engineering, with 5.6 and 4.6 percent, respectively. These publications will be used in section 3.
Table 2. Literature source distribution

Source: The author(s)’ own (2017)
3 Literature review
3.1 Blowout Preventer System
Regarding Martins (2015, p. 1), Blowout Preventer “consists of an embedded set of valves that are remotely controlled from the rig, acting as a main block out barrier in the well control”.
The BOP is the second barrier of well control. The primary barrier is the hydrostatic pressure provided for the weighting of the drilling mud to counterbalance pressure from the reservoir (Alme et Huse, 2013). According to Sattler (2013, p. 1) “although not the primary resource used by the driller for well control, they are correctly understood as one of the last line of defenses”. Figure 3 present an example of BOP.
Figure 3. Blowout Preventer
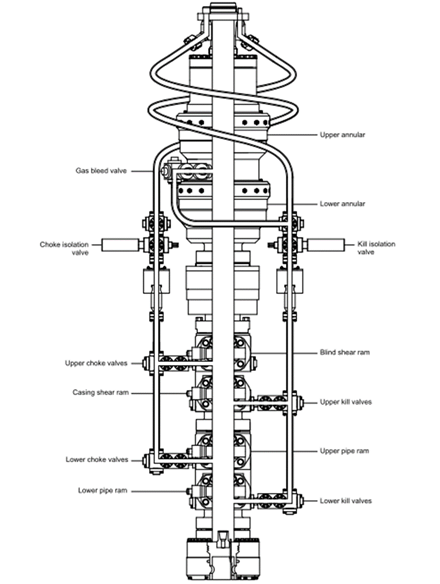
Source: API STD 53, 2016
When the reservoir pressure exceeds, for many reasons, the drilling-fluid pressure, there is an uncontrolled influx of formation of fluids into wellbore. The main function of the BOP is to close the wellbore and circulate drilling fluid with higher density in order to regain the hydrostatic control of the well (ISO 14224, 2016).
BOP has long been understood as one of the most safety critical devices of all rig equipment, because they are developed to handle with extreme erratic pressures and uncontrolled flow (kick) coming from a well reservoir during drilling operations (Alme et Huse, 2013; Sattler, 2013). In addition, ISO 14224 (2016) subdivided the BOP equipment in: preventers, valves and lines; hydraulic connectors; flexible joint; primary control; and backup control.
3.1.1 Preventers, Valves and Lines
The Blowout Preventer has basically two types of preventers: annular preventers and the other is ram preventers (single and double rams, including shear rams) (Alme et Huse, 2013; Han, 2015).
API Standard 53 (2016, p. 3) defines annular as “a blowout preventer that uses a shaped elastomeric sealing element to seal the space between the tubular and the wellbore or an open hole”. Regarding the Deepwater Horizon Study Group (2011, p. 26), “annular preventers are rubber donut shaped seals that close around the pipe, sealing the well. They can also seal the well with an absence of pipe in the hole”.
Ram preventers can be further divided into two types: pipe rams and shear rams (Alme et Huse, 2013). Pipe rams are metal bars with circular rubber ends such that they can seal the well by clamping around the drill pipe, sealing the annulus (Deepwater Horizon Study Group, 2011). According Saetre (2015, p. 10), “there are pipe rams in different sizes, depending on the diameter of the tubular being run. There are also variable pipe rams that can handle multiple tubular diameters”.
API SPEC 16C (2016, p. 4) defines choke and kill lines as “a high-pressure line that allows fluids to be pumped into or removed from the well with the BOPs closed”. The main function of the choke and kill lines and valves is to circulate out a kick (Klakegg, 2012). The choke and kill line systems are basically divided in three main parts: flexible jumper hoses in the moon pool; integral riser lines and BOP attached lines from the connection to the integral riser lines to the outer choke and kill valve outlets (Holand et Rausand, 1999).
3.1.2 Hydraulic Connectors
All BOPs are equipped with two hydraulic connectors (Holand and Rausand, 1999). They are hydraulically actuated drill-through equipment that locks and seals on end connections (API SPEC 16A, 2017). According to Holand and Rausand (1999), these connectors are, in principle, identical; however, the wellhead connector is usually rated to a higher pressure and has the same rate pressure as rams’ preventer. The Lower Marine Riser Package (LMRP) connector is a hydraulically operated connection connector that joins the LMRP to the top of the lower BOP’s stack and enables, for safety reasons or for repairs/maintenance, LMRP to be separated and removed from the BOP’s stack (API SPEC 16D, 2013; Drægebø, 2014).
3.1.3 Primary Control System
According to API SPEC 16D (2013, p. 25), the “control system shall afford control of all the subsea BOP stack functions, including remotely adjustable pressure regulator settings”. It is the brain of the subsea BOP system (Saetre, 2015). The BOP control system consists of two basic elements: electrical and hydraulic components (Shanks et al., 2003, p. 2). A multiplex control system (MUX) is an electro-hydraulic system applied to control the functions of BOP (Saetre, 2015). The main function of the MUX control system is to control and monitor the hydraulically operated subsea BOP’s stack equipment through the subsea line control pod, designated Blue and Yellow (NOV 10645935-MAN, no date). Regarding API SPEC 16D (2013, p. 31), the MUX control system “employs multi-conductor armored subsea umbilical cables deployed from storage reels aboard the vessel. The cables transmit coded commands that activate solenoid operated pilot valves in the subsea pods”.
3.1.4 Backup System
In the event in which the power fluid supply or pilot signals is lost, a backup control system may be employed to operate selected functions. A backup system has an independent control system that may be used to operate critical functions such as well control, disconnection and/or recovery (API SPEC 16D, 2013). The BOP backup system includes acoustic control systems, ROV (Remotely Operated Vehicle) operated control systems, dead man and/or auto shear system, and the main hydraulic supply of the control system may be powered by a shared accumulator. (API SPEC 16D, 2013). Other papers’ publications and standards can be found in Table 3.
Table 3. BOP system publications survey
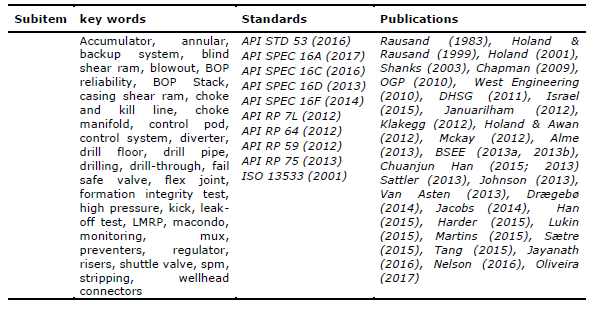
Source: The authors’ own (2017)
3.2 Reliability concepts
In order to understand the approach to reliability concepts for the implementation of CBM and PHM a brief explanation of failure data, Reliability Centered Maintenance (RCM) and Failure Mode and Effect Analysis (FMEA) and their variations with mechanism and criticality will be addressed in this section.
3.2.1 Failure data and analysis
Failure mode is a way failure occurs (ISO 14224, 2016) or generally describes the way the failure occurs and its impact on equipment operation (MIL-STD-1629, 1980). Failure mechanism is "the physical, chemical, electrical, thermal or other process which results in a failure (MIL-STD-721 C, 1981). Failure cause is the circumstance occurred during design, manufacture or use that has led to a failure (ISO 14224, 2016). Failure effect is “the consequence(s) a failure mode has on the operation, function or status of an item (MIL-STD-721 C, 1981), or what happens when a failure mode occurs (ADS-79D-HDBK, 2013).
3.2.2 Reliability Centered Maintenance (RCM)
The RCM concept was introduced by the aviation industry and has shaped the basis structure for planning airplane maintenance. Its approach improved the cost-effectiveness and maintenance control in military branches and industries, thus increasing the systems’ reliability and safety (Rausand, 1998; Rausand et Hoyland, 2004).
Military Standards 2173 (1981, p. 11) treat it as “a disciplined logic or methodology used to identify preventive maintenance tasks to realize the inherent reliability of equipment, with the least expenditure of resources”. Regarding US Department of Defense (2011, p. 25), RCM is “a logical, structured process used to determine the optimal failure management strategies for any system, based on system reliability characteristics and the intended operating context”. Furthermore, it “should be applied to ensure the system achieves the desired levels of safety, reliability, environmental soundness, and operational readiness in the most cost-effective manner”.
The inherent equipment’s reliability is a function of the design and the built quality. Reliability Centered Maintenance is a technique that considers the functional consequences of failures and also uses operating experience information resources, which helps to develop a preventive maintenance program (Lannoy et Procaccia, 1996; Rausand, 1998; Rausand et Hoyland, 2004).
3.2.3 FMEA / FMMEA / FMECA
Failure mode and effect analysis (FMEA) was one of the first techniques for failure analysis. It was developed by reliability engineers on the aerospace industry, at Grumman Aircraft Corporation in the 1950 and 1960s. It is a formal design methodology to study problems, which might arise from the malfunctions of military systems (Bowles et Perez, 1995; Rausand et Hoyland, 2004; Sharma et Sharma, 2010).
FMEA is a very powerful and efficient analytical technique, which is broadly used in engineering projects to identify the failure modes of each of the functional blocks of system and decrease or even eliminate potential failure during the design process (Rausand et Hoyland, 2004; Xiao et al., 2011). In addition, FMEA provides quantitative and qualitative necessary measures to guide the product design implementation and for reliability analyses and maintenance program as well (Rausand et Hoyland, 2004; Chen et LeeJih, 2007).
Failure mode, effect and critical analysis (FMECA) analyzes and ranks the risk associated with products and process, prioritizes them for remedial action, aiming to reduce their risks and to provide information for making risk management decisions (Puente et al., 2002; Narayanagounder et Gurusami, 2009; Barends et al., 2012; Liu et al., 2013).
According to Vachtsevanos (2006, p. 20) “advanced FMECA studies may recommend algorithms to extract optimal fault features or condition indicators, detect and isolate incipient failures, and predict the remaining useful life of critical components. Such studies generate the template for diagnostic algorithms”.
Cheng et al. (2010b, p. 5778) shows that Failure mode, mechanism effect analysis (FMMEA) “is a methodology used to identify the critical failure mechanisms and models for all potential failure modes of a product under expected operational and environmental conditions. The output of the FMMEA process is a list of critical failure modes and mechanisms that enable us to identify the parameters to monitor, and the relevant physics-of-failure models to predict the remaining life of the component”. Introducing a failure mechanism to analysis is important in order to provide guidelines for determining the major operational stresses and environmental and operational parameters by prioritizing the failure mechanisms based on their event and severity (Cheng et al., 2010b). A summary with keywords, standards and others reference publications can be found in Table 4 for further studies on failure analysis and reliability.
Table 4. Failure data and analysis survey
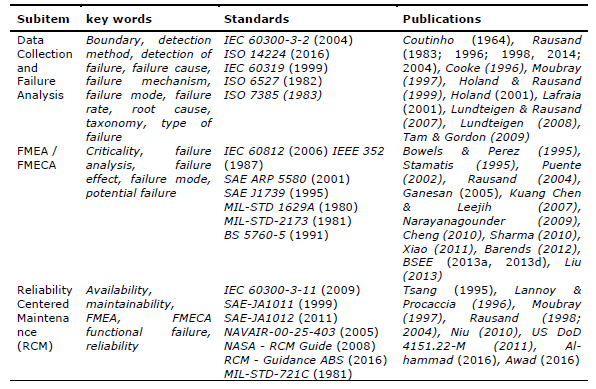
Source: The authors’ own (2017)
3.3 Condition Monitoring, CBM and PHM
3.3.1 Condition Monitoring / Detection
ISO 13372 (2004, page 1) defined condition monitoring as a “detection and collection of information and data that indicate the state of a machine”. Condition monitoring can also be called as “Detection” or State Detection (SD), and allows distinguishing anomalous behaviors, comparing gathered data against baseline parameters, enabling detection and reporting abnormal events on the machine or system (ISO 13374-1, 2003; ISO 13379, 2012).
In fact, Niu (2010, p. 7) states that “condition monitoring is the process of monitoring a condition parameter of machinery, such that a significant change is indicative of a developing failure” and it could be related to a specific variable and, when this parameter is outside of defined range, the system triggers a warning or alarm (López-Campos et al., 2013). A trend on the system’s critical component deterioration can also be identified through a condition monitoring data (Yam et al., 2001).
3.3.2 Condition-based Maintenance (CBM)
ISO 13772 (2004, p. 1) defined CBM as “Maintenance performed as governed by condition monitoring programs” and EN 13306 (2010) as “Preventive maintenance that includes a combination of condition monitoring and/or inspection and/or testing, analysis and subsequent maintenance actions”.
Jardine (2006, p. 1484) emphasized that “no matter how good the product design is, products deteriorate over time since they are operating under certain stress or load in the real environment, often involving randomness”. He also highlighted that diagnostics and prognostics are important aspects to determine the influence of this parameter in a CBM program. Hence, maintenance has been introduced as an efficient way to assure a satisfactory level of reliability during the useful life of a physical asset.
The Condition-Based Maintenance can identify stress, physical changes on equipment conditions, performance operation and environment to contribute to asset’s failure reduction, including root-cause detection in a short time and helping to select subsequent actions on decision making (Bengtsson, 2004; Kothamasu et al., 2006; Guillén et al., 2016). In addition, CBM is useful for the safety system that can increase safety by detecting problems in advance before serious problems occur. It means, get a high-quality assurance (Shin et Jun 2015).
According to Guillén (2016, page 173), CBM Programs have complexity causes and implementation challenges. “A crucial aspect of this process is to identify equipment patterns triggering warning or alarm messages. The objective is to detect or estimate equipment degradation from normal conditions; consequently, to determine the degradation nature and behavior could be difficult”. Figure 4 shows the process to implement a CBM according ISO 13374.
Figure 4. CBM process
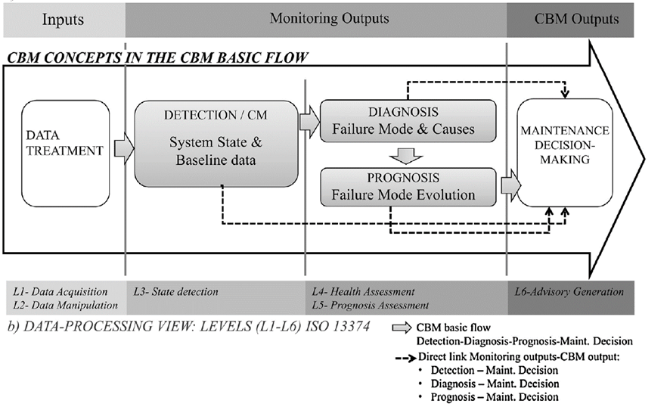
Source: Guillén, 2016
3.3.3 Prognostic Health Management (PHM)
Recent approach for CBM evolved to Prognosis and Health Management (PHM), which provides powerful capabilities through dynamic pattern recognition for physical understanding of the useful life of an equipment and system (Vachtsevanos et al., 2006; Lee et al., 2011; Guillén et al., 2016).
Regarding Cheng (2010, p. 5774) “Prognostics and health management (PHM) is an enabling discipline consisting of technologies and methods to assess the reliability of a product in its actual life cycle conditions to determine the advent of failure and mitigate system risk”.
Prognostics and health management (PHM) generally rely highly on the sensor systems to obtain long-term accurate information of environmental, operational, and performance-related parameters to assess the health of a product, as well as to provide anomaly detection, fault isolation, and predict the equipment’s future health conditions as well as the Remaining Useful Life (RUL) (Cheng et al. 2010a; Tian et al. 2011).
PHM implies the understanding of the RUL concepts. Jardine (2006, p. 1495) highlights that the remaining useful life “refers to the time left before observing a failure given the current machine age and condition, and the past operation profile’. This approach aims to provide users with an integrated and full view of the health state of some equipment or an overall system. It brings benefits such as predicting failure; reducing unscheduled corrective maintenance and downtime, improving equipment performance and reducing the maintenance cost of equipment due to decreasing inspection and inventory cost (Kothamasu et al., 2006; Cheng et al., 2010b; Lee et al., 2011).
The U.S. Department of Defense policy document (2004) described the importance of PHM as “program managers that shall optimize operational readiness through affordable, integrated, embedded diagnostics and prognostics, embedded training and testing, serialized item management, automatic identification technology, and iterative technology refreshment”.
3.3.4 Parameters
ISO 13772 (2004, p. 7) defined parameters as “measurable variables”. In fact, Cheng et al. (2010a, p. 856) describes that “parameters include operational and environmental loads, as well as the performance conditions of the product, as for example, temperature, vibration, shock, pressure, acoustic levels, strain, stress, voltage, current, humidity levels, contaminant concentration, usage frequency, usage severity, usage time, power, and heat dissipation”. Example of parameters and its domain are listed in figure 5.
Figure 5. Parameters for PHM applications.
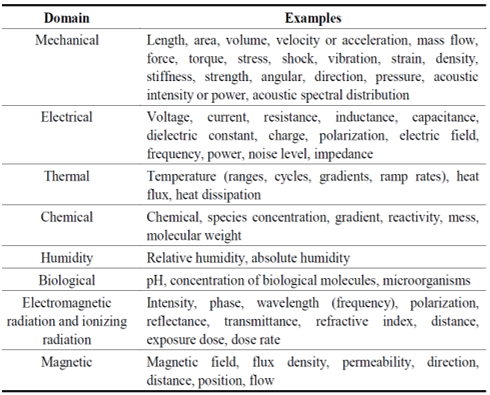
Source: Guillén, 2016
The CBM / PHM approach requires monitoring many product parameters to evaluate the equipment health. Hence, it is important to determine the items and ultimately the parameters that need to be monitored. Moreover, the characteristics of these parameters, such as the possible range and frequency, should be understood. The characteristics can be obtained through the history or product specification data (Cheng et al., 2010b; Guillén et al., 2016). ISO 17359 (2002) gives an example of parameters by machine type, such as temperature, pressure, fluid flow, noise, vibration, oil characteristic and speed for pumps.
It is important to consider all stages of product life cycle, such as manufacturing, shipment, storage, handling and operation. The component failure can be related to one of this stage and parameter monitoring should be necessary (Cheng et al., 2010b).
3.3.5 Symptoms
ISO 13372 (2004, p. 7) defined symptoms as “perception, made by means of human observations and measurements (descriptors), which may indicate the presence of one or more faults with a certain probability”. Symptom infers that something happened (fault) in the system and it can detect, or measure, some evidence of it (perception of fault). It is also defined as a qualitative description of specific causes or effect that can be measured. Symptom can be related to one or more failure modes and one failure mode can have one or more symptoms (Guillén et al., 2016).
For Vactchesvanos (2006, p. 20) “fault symptoms that are suggestive of the system’s behavior under fault conditions; and the sensors/monitoring apparatus required to monitor and track the system’s fault-symptomatic behaviors”. Figure 6 presents some symptoms related to fault.
3.3.6 Diagnostic / Diagnosis
ISO 13372 (2004, page 7) defined diagnostic as an “examination of symptoms and syndromes to determine the nature of faults or failures” and diagnosis as a “result of the diagnostics process”. For Vichare et Pecht (2006, p. 222) “Diagnostics pertain to the detection and isolation of faults or failures”.
Diagnostic deals with fault detection, isolation, and identification when is recognized as a deviation from the expected level (Jardine, 2006; Yam 2001). It means that it is a task to indicate whether something is going wrong in the system. It is required when fault prediction of prognostic fails and a failure occurs and also can be useful to provide more accurate event data and, hence, better structure the CBM and PHM model (Jardine et al., 2006).
3.3.7 Prognostic / Prognosis
ISO 13372 (2004, p. 7) defined prognostic as the “analysis of the symptoms of faults to predict future condition and the remaining useful life”. On the other hand, ISO 13381 (2004, p. 1) defined prognosis as “estimation of time to failure and risk for one or more existing and future failure modes”. According to Jardine et al. (2006, p. 1484–1485) “prognostics deal with fault prediction before it occurs” and (2006, page 1495) it “predicts how much time is left before a failure occurs (or, one or more faults), given the current machine condition and past operation profile”.
According to ISO 13381-1 (2004, p. v) “prognosis of future fault progressions requires foreknowledge of the probable failure modes, future duties to which the machine will/might be subjected, and a thorough understanding of the relationships between failure modes and operating conditions”. ISO 13381-1 (2004, p. 2–3) described some pre-requisite for providing a prognostic, such as historical operation data, and maintenance and failure data; failure modeling processes that can include statistics, failure mode influence factors; reliability and safety data; alarm limits; Initiation criteria, and failure definition set points for all parameters, and descriptors and so on. Figure 6 shows an example of symptom and parameter for each fault.
Prognosis is associated with failure mode behavior and prediction of the remaining useful life of the equipment or, in other words, the estimation of the time to failure based on failure mode risks. Thus, it became possible to plan the replacement of the equipment before the end of useful life (Chen et al., 2012; Tobon-mejia et al., 2012; Shin et Jun, 2015; Guillén et al., 2016) and to save extra unplanned maintenance cost. Furthermore, it is more efficient than diagnostics in order to achieve zero-downtime performance. Nevertheless, prognostics cannot completely replace diagnostics because there are some faults and failures that are not predictable (Jardine, Lin and Banjevic, 2006).
Table 5 presents a summary with keywords, standards and others reference publications for deeper understanding of the CBM and PHM concepts.
Figure 6. Fan faults matched to symptoms and measure parameters.
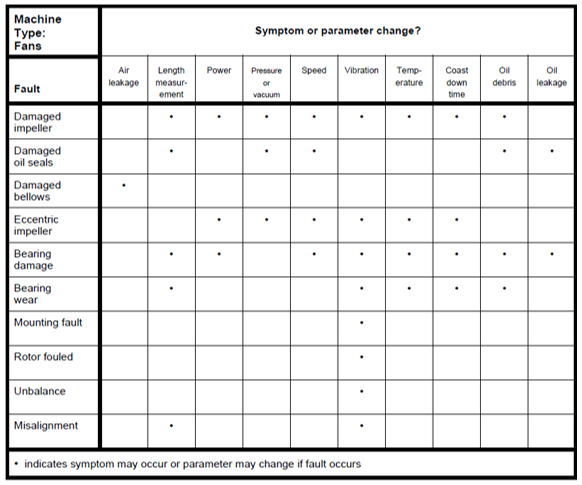
Source: ISO 17359 (2002)
Table 5. CBM and PHM survey
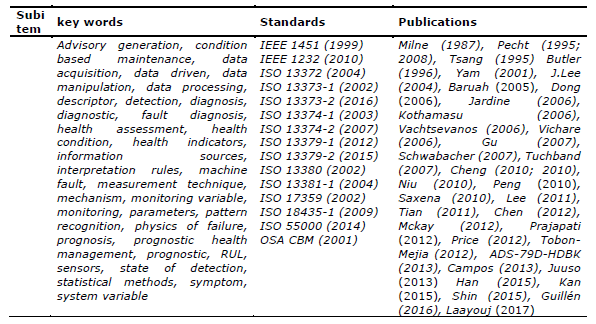
Source: The authors’ own (2017)
3.4 Reliability approach for CBM and PHM
The relationship between CBM and RCM (Reliability Centered Maintenance) by using RCM steps (operational context definition, FMEA/FMECA, RCM logic, etc.) is essential on design process phases in their CBM proposals (López-Campos et al., 2013; Guillén et al., 2016).
According to ISO 17359 “It is recommended to perform a failure modes and effects analysis (FMEA) or failure mode effect and criticality analysis (FMECA) in order to identify expected faults, symptoms, and potential parameters to be measured that indicate the presence or occurrence of the faults”.
Niu (2010) proposed CBM architecture integrated with RCM in order to achieve cost-effective maintenance strategy. This structure starting with an asset or component identification, determines its functional failure and failure mode and effect (FMEA), and integrating with sensors of condition monitoring and then reaching a diagnostic (Health Assessment) and prognostic to decision support, as shown in figure 7.
Figure 7. Integration between the RCM and CBM structures
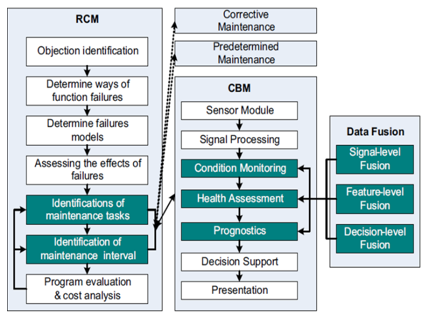
Source: Niu (2010)
Vachtsevanos (2006, p. 18) highlighted that “understanding the physics of failure mechanisms constitutes the cornerstone of good CBM/PHM system design”. In another view, Cheng et al. (2010b, p. 5780) shows that “FMMEA prioritizes the failure mechanisms based on their occurrence and severity in order to provide guidelines for determining the major operational stresses and environmental and operational parameters”. According to Campos (2013, p. 535) “a RCM analysis identifies the critical failure modes and monitoring parameters (MPs) relevant to diagnosis/prognosis”.
Indeed, the management of CBM program is extremely complex because it requires handling massive information and its interfaces with systems, operations, and environment. Guillén (2016) proposes a series of steps that should be performed earlier to develop a CBM framework, even though they are not directly associated with CBM / PHM. These steps were divided in blocks and are represented in Figure 8 with an overview of elements, objectives, and references and methods to develop each block.
Figure 8. Summary of the blocks in the framework for CBM management
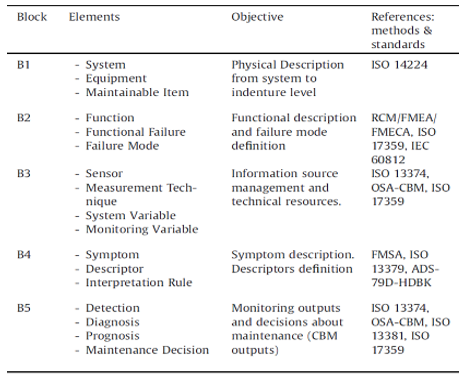
Source: Guillén, 2016
In order to shows all block development, a representation using a single table of all possible CBM activities was shown in figure 9. Failure mode, symptom, monitoring variable, information sources, descriptor, type of monitoring condition (detection, diagnostic and prognostic) and the interpretation rules are the main information of the CBM framework.
Figure 9. Example of the activities to CBM / PHM solution.
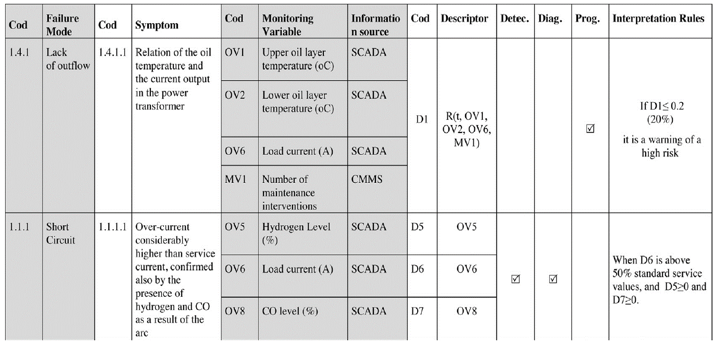
Source: Guillén, 2016
4 Conclusions
According to Moczydlower (2017), VP Technology Development at Embraer, prognostics and diagnostics is the future on reliability of digital age to offer immediate gains on assets availability through increased failure predictability and support decision-making in operation and maintenance management.
Currently, there is a tendency to provide a Real-time Monitoring technology and to achieve higher levels of BOP reliability and operational safety. However, a raw real-time monitoring data is not enough and it must be coupled with good analytical tools that are themselves capable of analyzing those data stream and providing concise results for operation decision making (Oliveira et al., 2017) and increasing maintenance strategy. Certainly, understanding how operational and environmental parameters influence component failure and their straight relationship with equipment availability is essential to reach high levels of reliability through prognostics and diagnostics; however, it is still far away from reality. This fact is closely related to the industry culture, such as: the impartiality in legislation on the manufacture’s responsibility to provide failure root cause analysis and to increase BOP reliability; and the relationship between manufacturer, operators and drilling contractors to share relevant information of operation and failure.
In addition, there is lack of knowledge of an entire hierarchical chain on operators and contractors about the importance of performing reliability engineering and the absence of structure that allows collecting high quality failure data, as presented by Colombo et Leibsohn (2017). This reflects straightly the scarcity of publications related to the application of condition monitoring, CBM and PHM for BOP.
This paper has called the reader’s attention toward CBM and PHM concepts applied on high reliability industries as a great research source for future works on the BOP system. Literature review shows how actively researchers are engaged in real-time condition monitoring, CBM capabilities and provides literature using reliability approach during the process to obtain them.
Finally, the paper carries the importance to develop reliability studies and to reach a BOP Prognostic Health Management in order to increase maintenance strategy and decision making on operations, looking forward to operational safety and avoiding disasters and also downtimes.
References
ADS-79D-HDBK (2013), “Handbook for Condition Based Maintenance Systems for Us Army Aircraft Systems”, Aeronautical Design Standard.
Al-hammad, A. et al. (2016),” A SWOT analysis of reliability centered maintenance framework”, Escolha - Journal of Quality in Maintenance Engineering, Vol. 22, No. 2, pp. 29–39. doi: 10.1108/13552510810877674.
Alme, I.; Huse, J. (2013), “BOP Reliability Monitored Real Time”, European HSE Conference and Exhibition, pp. 16–18. doi: 10.2118/164987-MS.
American Bureau of Shipping - ABS (2016), Guide for Surveys Based on Machinery Reliability and Maintenance Techniques, ABS, New York.
API RP 59 (2012), “Recommended Practice for Well Control Operations”, American Petroleum Institute.
API RP 64 (2012), “Recommended practices for diverter systems equipment and operations”, American Petroleum Institute.
API RP 75 (2013), “Recommended Practice for Development of a Safety and Environmental Management Program for Offshore Operations and Facilities”, American Petroleum Institute.
API RP 7L (2012), “Procedures for Inspection, Maintenance, Repair, and Remanufacture of Drilling Equipment”, American Petroleum Institute, pp. 1–14.
API SPEC 16A (2017), “Specification for Drill-through Equipment”, American Petroleum Institute.
API SPEC 16C (2016), “Choke and Kill Equipment”, American Petroleum Institute.
API SPEC 16D (2013), “Specification for Control Systems for Drilling Well Control Equipment and Control Systems for Diverter Equipment”, American Petroleum Institute.
API SPEC 16F (2014), “Specification for Marine Drilling Riser Equipment”, American Petroleum Institute.
API STD 53 (2016), “Blowout Prevention Equipment Systems for Drilling Wells”, American Petroleum Institute.
Asten, P. V. (2013), “Pull or No-pull: Risk-based Decision Support for Subsea Blowout Preventers (BOPs)”, Society of Petroleum Engineers, available from: https://doi.org/10.2118/166581-MS (Access: 20 Feb. 2018).
Awad, M.; As’ad, R. A. (2016), “Reliability centered maintenance actions prioritization using fuzzy inference systems”, Journal of Quality in Maintenance Engineering, Vol. 22, No. 4, pp. 433–52. doi: 10.1108/JQME-07-2015-0029.
Barends, D. M. et al. (2012), “Risk analysis of analytical validations by probabilistic modification of FMEA”, Journal of Pharmaceutical and Biomedical Analysis, Vol. 64–65, pp. 82–86. doi: 10.1016/j.jpba.2012.02.009.
Baruah, P.; Chinnam, R. B. (2005), “HMMs for diagnostics and prognostics in machining processes”, International Journal of Production Research, Vol. 43, No.6, pp. 1275–93. doi: 10.1080/00207540412331327727.
Bengtsson, M. (2004), “Condition Based Maintenance Systems an Investigation of Technical Constituents and Organizational Aspects”, PhD Thesis, Department of Innovation, Design, and Product Development, Mälardalen University.
Bowles, J. B.; Perez, C. E. (1995), “Fuzzy logic prioritization of failures in a system failure mode, effects and criticality analysis”, Reliability Engineering and System Safety, Vol.50, No. 2, pp. 203–13. doi: 10.1016/0951-8320(95)00068-D.
BS 5760-5 (1991), Reliability of systems, equipment and components. Guide to failure modes, effects and criticality analysis (FMEA and FMECA).
Bureau of Safety and Environmental Enforcement (2013a), Blowout Preventer (Bop) Failure Mode Effect Criticality Analysis (Fmec) -3 for.
Bureau of Safety and Environmental Enforcement (2013b) Blowout Preventer (Bop) Reliability, Availability, And for The Maintainability (Ram) Analysis 1.
Bureau of Safety and Environmental Enforcement (2013c), Maintenance and Inspection Study Final Report.
Bureau of Safety and Environmental Enforcement (2013d), Summary of Blowout Preventer (BOP) Failure Mode Effect Criticality Analyses (FMECAS).
Butler, K. L. (1996), “An expert system based framework for an incipient failure detection and predictive maintenance system”, in International Conference on Intelligent Systems Applications to Power Systems (Isap'96), January 28 - February 2,1996, Orlando, Florida.
Chapman, F. M. et al. (2009), “OTC 20059 Deepwater BOP Control Monitoring — Improving BOP Preventive Maintenance with Control Function Monitoring”, Vol.1, pp. 1–8.
Chen, J. K.; LeeJih, Y. C. (2007), “Utility priority number evaluation for FMEA”, Journal of Failure Analysis and Prevention. doi: 10.1007/s11668-007-9072-y.
Chen, Z. S. et al. (2012), “A technical framework and roadmap of embedded diagnostics/prognostics for complex mechanical systems in PHM systems”, IEEE Transactions on Reliability, Vol. 61, No. 2, pp. 314-22. doi: 10.1109/PHM.2011.5939468.
Cheng, S. et al. (2010a), “A Wireless Sensor System for Prognostics and Health Management”, IEEE Sensors Journal, Vol.10, pp. 10–2.
Cheng, S. et al. (2010b), “Sensor systems for prognostics and health management”, Sensors, Vol.10, No. 6, pp. 5774–97. doi: 10.3390/s100605774.
Chze, L. P. et al. (2016), “Optimising Data Processing for Subsea System Surveillance Through Subsea Condition Monitoring”, Offshore Technology Conference, available from: https://doi.org/10.4043/26842-MS (Access: 20 Feb 2018).
Colombo, D.; Leibsohn, A. (2017), “Transferindo conhecimentos de confiabilidade aeronáutica para a construção de poços de petróleo", artigo apresentado no 15° Simpósio Internacional de Confiabilidade, Belo Horizonte, MG, 07-08 ago. 2017.
Cooke, R. M. (1996), “The design of reliability data bases, part II: competing risk and data compression”, Reliability Engineering & System Safety, Vol. 51, No.2, pp. 209–23. doi: 10.1016/0951-8320(95)00118-2.
Coutinho, J. S. (1964), “Failure-effect analysis”, Transactions of the New York Academy of Sciences.
Deepwater Horizon Study Group (2011), “Final Report on the Investigation of the Macondo Well Blowout”, pp. 1–124.
Delmar Engineering (2010), Blowout Prevention Equipment Reliability Joint Industry Project (Phase I – Subsea), Houston, TX.
DoD 5000.2 (2004), Performance Based Logistics. In Defense Acquisition Guidebook, Fort Belvoir, VA.
Dong, M.; He, D. (2006), “Hidden semi-Markov model-based methodology for multi-sensor equipment health diagnosis and prognosis”, European Journal of Operational Research, Vol. 178, No. 3, pp. 858–78. doi: 10.1016/j.ejor.2006.01.041.
Drægebø, E. (2014), Reliability Analysis of Blowout Preventer Systems, Master’s Thesis; NTNU.
EN 13306 (2010), “Maintenance - Maintenance Terminology”.
Ganesan, S. et. al. (2005), “Identification and Utilization of Failure Mechanisms to Enhance FMEA and FMECA”.
Gu, J. et al. (2007), “Prognostics implementation of electronics under vibration loading”, Microelectronics Reliability, Vol. 47, No. 12, pp. 1849-56. doi: 10.1016/j.microrel.2007.02.015.
Guillén, A. J. et al. (2016), “A framework for effective management of condition-based maintenance programs in the context of industrial development of E-Maintenance strategies”, Computers in Industry, Vol. 82, pp. 170–85. doi: 10.1016/j.compind.2016.07.003.
Hals, T.; Molnes, E. (1984), Reliability of Subsea BOP Systems ‐Phase II Control Systems, SINTEF Industrial Management, Trondheim.
Han, C. et al. (2015), “Study of the damage and failure of the shear ram of the blowout preventer in the shearing process”, Engineering Failure Analysis, Vol. 58, pp. 83–95. doi: 10.1016/j.engfailanal.2015.08.025.
Han, C.; Zhang, J. (2013), “Study on well hard shut-in experiment based on similarity principle and erosion of ram rubber”, Engineering Failure Analysis, Vol. 32, pp. 202–8. doi: 10.1016/j.engfailanal.2013.03.016.
Han, Z. (2015), “Stochastic Modelling for Condition Based Maintenance”, Master Thesis, Department of Production and Quality Engineering, Norwegian University of Science and Technology.
Harder, C. et al. (2015), “Real Time Data Monitoring Experience Results in Enhanced Safety and Efficiency”, SPE/IADC Drilling Conference and Exhibition. doi: 10.2118/173090-MS.
Holand, P. (1986), “Reliability of Subsea BOP Systems - Phase III Testing and Maintenance”, SINTEF.
Holand, P. (1989), “Subsea BOP Systems, Reliability and Testing - Phase V”, SINTEF.
Holand, P. (1997), “Reliability of Subsea BOP Systems for Deepwater Application & Fault Tree Analysis”, SINTEF.
Holand, P. (2001), “Reliability of Deepwater Subsea Blowout Preventers”, SPE Drilling & Completion, Vol. 1, pp. 12–18. doi: 10.2118/70129-pa.
Holand, P.; Awan, H. (2012), Reliability of Deepwater Subsea BOP Systems and Well Kicks.
Holand, P.; Rausand, M. (1987), Reliability of Subsea BOP Sandtorv Systems, Reliability Engineering and System Safety, Vol. 19, pp. 263-275.
Holand, P.; Rausand, M. (1999), “Reliability of Subsea BOP Systems for Deepwater Application, Phase II DW”, SINTEF. doi: 10.1017/CBO9781107415324.004.
Holand, P.; Rausand, M. (2001), Deepwater Kicks and BOP Performance, SINTEF, doi: 10.1017/CBO9781107415324.004.
Hwang, H. (2015), “Introduction to a Condition-based Maintenance Solution for Offshore Platforms”, International Society of Offshore and Polar Engineers, The Twenty-Fifth International Ocean and Polar Engineering, 21-26 June, Kona, Hawaii, USA.
IEC 60300-3-11 (2009), “Dependability management ‐ Part 3-11: Application guide - Reliability centred maintenance”.
IEC 60300-3-2 (2004), “Dependability management - Part 3: Application guide - Section 2: Collection of dependability data from the field”.
IEC 60319 (1999), “Presentation and specification of reliability data for electronic components”.
IEC 60812 (2006), “Analysis techniques for system reliability - Procedure for failure mode and effects analysis (FMEA)”.
IEEE 1232 (2010), “Artificial Intelligence Exchange and Service Tie to All Test Environments”.
IEEE 1451 (1999), “Smart Transducer Interface for Sensors and Actuators - Common Functions, Communication Protocols, and Transducer Electronic Data Sheet (TEDS) Formats”.
IEEE 352 (1987), “Reliability Analysis of Nuclear Power Generating Station Safety Systems, Guide for General Principles”.
International Association of Oil & Gas Producers (2010), Risk Assessment Data Directory.
ISO 13372 (2004), “Condition monitoring and diagnostics of machines—Vocabular”, International Organization, Vol.3.
ISO 13373-1 (2002), Condition monitoring and diagnostics of machines - Vibration condition monitoring - Part 1: General procedures.
ISO 13373-2 (2016), Condition monitoring and diagnostics of machines - Vibration condition monitoring - Part 2: Processing, analysis and presentation of vibration data.
ISO 13374-1 (2003), “Condition monitoring and diagnosis of machines—Data processing, communication and presentation—Part 1: General guidelines”, International Organization for Standardization.
ISO 13374-2 (2007), “Preview Condition monitoring and diagnostics of machines -- Data processing, communication and presentation -- Part 2: Data processing”, International Organization for Standardization.
ISO 13379 (2012), “Condition monitoring and diagnosis of machines—Data interpretation and diagnosis techniques—Part 1: General guidelines”, International Organization for Standardization.
ISO 13379-2 (2015), Condition monitoring and diagnostics of machines - Data interpretation and diagnostics techniques - Part 2: Data-driven applications.
ISO 13380 (2002), Condition monitoring and diagnostics of machines - General guidelines on using performance parameters.
ISO 13381-1 (2004) ‘Preview Condition monitoring and diagnostics of machines -- Prognostics -- Part 1: General guidelines’, International Organization for Standardization.
ISO 13533 (2001), Petroleum and natural gas industries - Drilling and production equipment - Drill-through equipment.
ISO 14224 (2016), Petroleum, petrochemical and natural gas industries — Collection and exchange of reliability and maintenance data for equipment.
ISO 17359 (2002), “Condition monitoring and diagnostics of machines - General guidelines”, International Organization for Standardization, Vol. 50.
ISO 18435-1 (2009), Industrial automation systems and integration - Diagnostics, capability assessment and maintenance applications integration - Part 1: Overview and general requirements.
ISO 55000 (2014), Asset management - Overview, principles and terminology.
ISO 6527 (1982), Nuclear power plants - Reliability data exchange - General guidelines.
ISO 7385 (1983), Nuclear power plants- Guidelines to ensure quality of collected data on reliability.
Israel, R. et al. (2015), “Well Advisor - Integrating Real-time Data with Predictive Tools, Processes and Expertise to Enable More Informed Operational Decisions”, SPE/IADC Drilling Conference and Exhibition. doi: 10.2118/173061-MS.
Jacobs, T.; Writer, J. P. T. T. (2014), “Blowout Preventer Technology BOP Monitoring Seeks to Reduce Downtime, Increase Insight”, Journal of Petroleum Technology, Vol. 66.
Januarilham, Y. (2012), “Analysis of Component Criticality in the Blowout Preventer”.
Jardine, A. K. S. et al. (2006), “A review on machinery diagnostics and prognostics implementing condition-based maintenance”, Mechanical Systems and Signal Processing, Vol. 20, No. 7, pp. 1483–1510. doi: 10.1016/j.ymssp.2005.09.012.
Jayanath, S. et al. (2016), “A Sub-Scale Experimental Test Method to Investigate the Failure of Variable Ram Blowout Prevention Valves”, Offshore Technology Conference. doi: 10.4043/27157-MS.
Johnson, C. et al. (2013), “BOP Testing - Qualification Tests, Test Facilities and the Efficient Means of Operating Them”, SPE/IADC Drilling Conference.
Juuso, E. K.; Lahdelma, S. (2013), “Intelligent performance measures for condition‐based maintenance”, Journal of Quality in Maintenance Engineering, Vol. 19, No. 3, pp. 278–94. doi: 10.1108/JQME-05-2013-0026.
Kan, M. S. et al. (2015), “A review on prognostic techniques for non-stationary and non-linear rotating systems”, Mechanical Systems and Signal Processing, Vol. 62, pp. 1–20. doi: 10.1016/j.ymssp.2015.02.016.
Klakegg, S. (2012), Improved methods for reliability assessments of safety-critical systems: An application example for BOP systems, Master thesis, Institutt for produksjons- og kvalitetsteknikk.
Kothamasu, R. et al. (2006), “System health monitoring and prognostics -a review of current paradigms and practices 1 Maintenance strategies and motivations for health monitoring l”, The International Journal of Advanced Manufacturing Technology, Vol. 28, pp. 1012–24. doi: 10.1007/978-1-84882-472-0_14.
Laayouj, N.; Jamouli, H. (2017), “Prognosis of degradation based on a new dynamic method for remaining useful life prediction”, Journal of Quality in Maintenance Engineering, Vol. 23, No. 2, pp. 239–55. doi: 10.1108/JQME-03-2016-0012.
Lafraia, J. R. B. (2001), Manual de Confiabilidade, Mantenabilidade e Disponibilidade, Qualitymark, Rio de Janeiro.
Lannoy, A.; Procaccia, H. (1996), “The EDF failure reporting system process, presentation and prospects”, Reliability Engineering and System Safety, Vol. 51, No. 2, pp. 147–58. doi: 10.1016/0951-8320(95)00112-3.
Lee, J. et al. (2011), “Self-maintenance and engineering immune systems: Towards smarter machines and manufacturing systems’, Annual Reviews in Control, Vol. 35, No. 1, pp. 111–22. doi: 10.1016/j.arcontrol.2011.03.007.
Lee, R. J. et al. (2004), An integrated platform for diagnostics, prognostics and maintenance optimization, in: The IMS'2004 International Conference on Advances in Maintenance and in Modeling, Simulation and Intelligent Monitoring of Degradations, Arles, France.
Liu, H. C. et al. (2013), “Risk evaluation approaches in failure mode and effects analysis: A literature review”, Expert Systems with Applications, Vol. 40, No. 2, pp. 828–38. doi: 10.1016/j.eswa.2012.08.010.
López-Campos, M. A. et al. (2013), “Modelling using UML and BPMN the integration of open reliability, maintenance and condition monitoring management systems: An application in an electric transformer system”, Computers in Industry, Vol. 64, No. 5, pp. 524–42. doi: 10.1016/j.compind.2013.02.010.
Lukin, N. et al. (2015), “Risk analysis of annular preventer performance in multiplexed submarines BOP based on ISO 31.000 and API 581 standards”, International Society of Offshore and Polar Engineers, The Twenty-fifth International Ocean and Polar Engineering, Conference, 21-26 June, Kona, Hawaii, USA.
Lundteigen, M. A. (2008), Safety instrumented systems in the oil and gas industry: Concepts and methods for safety and reliability, PhD thesis. doi: 10.13140/2.1.3663.7769.
Lundteigen, M. A.; Rausand, M. (2007), “Common cause failures in safety instrumented systems on oil and gas installations: Implementing defense measures through function testing”, Journal of Loss Prevention in the Process Industries, pp. 218–29. doi: 10.1016/j.jlp.2007.03.007.
Martins, F. et al. (2015), “Improving BOP Reliability Through an Integrated Management Approach”, Offshore Technology Conference OTC-26182-MS.
Mckay, J. et al. (2012), “Blowout Preventer (BOP) Health Monitoring”, Iadc/Spe 151182. doi: 10.2118/151182-MS.
Milne, R. (1987), “Strategies for Diagnosis’, IEEE Transactions on Systems, Man and Cybernetics, Vol. 17, No. 3, pp. 333–39. doi: 10.1109/TSMC.1987.4309050.
MIL-STD-1629 (1980), “Military Standard: Procedures for performing a failure mode, effects and criticality analysis”, available from: http://www.fmea-fmeca.com/milstd1629.pdf (access 20 Feb 2018).
MIL-STD-2173 (1981), “Reliability-Centered Maintenance Requirements for Naval Aircraft, Weapons Systems and Support Equipment”.
MIL-STD-721 C (1981), “Definitions of terms for reliability and maintainability”.
Moczydlower, D. (2017) “Confiabilidade para um novo patamar de eficiência operacional”, artigo apresentado no 15° Simpósio Internacional de Confiabilidade, Belo Horizonte, MG, 07-08 ago. 2017.
Moubray, J. (1997), Reliability-Centered Maintenance: RCM II, Industrial Press, North Carolina.
Narayanagounder, S.; Gurusami, K. (2009), “A New Approach for Prioritization of Failure Modes in Design FMEA using ANOVA’, World Academy of Science, Engineering and Technology, Vol. 3, No. 1, pp. 524-31.
NASA (2008), NASA Reliability Centered Maintenance Guide for Facilities and Collateral Equipment. doi: 10.1201/9781420031843.ch6.
Navair 00-25-403 (2005), Guidelines for the Naval Aviation Reliability-Centered Maintenance Process.
Nelson, W. R. (2016), “Improving Safety of Deepwater Drilling Through Advanced Instrumentation, Diagnostics, and Automation for BOP Control Systems”, Offshore Technology Conference. doi: 10.4043/27188-MS.
Niu, G. et al. (2010), “Development of an optimized condition-based maintenance system by data fusion and reliability-centered maintenance”, Reliability Engineering and System Safety, Vol. 95, No. 7, pp. 786–96. doi: 10.1016/j.ress.2010.02.016.
NOV 10645935-MAN (no date), “User’s Manual Multiplex Control Pod and BOP Stack Control System”, National Oilwell Varco, pp. 713–937.
Oliveira, L. F. et al. (2017), “Real-time Monitoring of BOP Reliability”, in Offshore Mediterranean Conference, Ravenna, pp. 1–13.
OSA CBM (2001), Open System Architecture for Condition-Based Maintenance.
Pecht, M. G. (2008), “Prognostics and Health Management of Electronics”, Wiley-Inter science.
Pecht, M.; Dasgupta, A. (1995), “Physics-of-failure: an approach to reliable product development”, IEEE 1995 International Integrated Reliability Workshop. Final Report, pp. 1–4. doi: 10.1109/IRWS.1995.493566.
Peng, Y. et al. (2010), “Current status of machine prognostics in condition-based maintenance: A review”, International Journal of Advanced Manufacturing Technology, Vol. 50, No. 1–4, pp. 297–313. doi: 10.1007/s00170-009-2482-0.
Prajapati, A. et al. (2012), “Condition based maintenance: a survey”, Journal of Quality in Maintenance Engineering, Vol. 18, No. 4, pp. 384–400. doi: 10.1108/13552511211281552.
Puente, J. et al. (2002), “A decision support system for applying failure mode and effects analysis”, International Journal of Quality & Reliability Management, Vol. 19, No. 2, pp. 137–50. doi: 10.1108/02656710210413480.
Qingfeng, W. et al. (2011), “Development and application of equipment maintenance and safety integrity management system”, Journal of Loss Prevention in the Process Industries, Vol. 24, No. 4, pp. 321–32. doi: 10.1016/j.jlp.2011.01.008.
Rausand, M. (1998), “Reliability centered maintenance”, Reliability Engineering and System Safety, Vol. 60, pp. 1–16. doi: 10.1201/9781420031843.ch6.
Rausand, M. (2014), Reliability of Safety-Critical Systems, Reliability of Safety-Critical Systems. doi: 10.1002/9781118776353.
Rausand, M. et al. (1983), “Reliability of Subsea BOP Systems”, pp. 19–24.
Rausand, M.; Hoyland, A. (2004), System Reliability Theory: Models, Statistical Methods, and Applications, 2nd ed., John Wiley & Sons, Hoboken, NJ. doi: 10.1109/WESCON.1996.554026.
Rausand, M.; ØIen, K. (1996), “The basic concepts of failure analysis”, Reliability Engineering and System Safety, Vol. 53, No. 1, pp. 73–83. doi: 10.1016/0951-8320(96)00010-5.
SAE ARP 5580 (2001), Recommended Failure Modes and Effects Analysis (FMEA) Practices for Non-Automobile Applications.
SAE J-1739 (1995), Potential Failure Mode and Effects Analysis (FMEA) Reference Manual.
SAE JA 1011 (1999), Evaluation Criteria for Reliability-Centered Maintenance (RCM) Processes.
SAE JA 1012 (2011), A Guide to the Reliability-Centered Maintenance (RCM) Standard.
Saetre, Ø. (2015), “Reliability assessment of subsea BOP control systems”, Master thesis, NTNU.
Sandtorv, H. A. et al. (1996), “Practical experiences with a data collection project: The OREDA project”, Reliability Engineering and System Safety, Vol. 51, No.2, pp. 159–67. doi: 10.1016/0951-8320(95)00113-1.
Sattler, J. P. (2013), “‘SPE 166869 “BOP Performance Post - Macondo - How Are We Doing?”’, (October), pp. 15–17. doi: 10.2118/166869-MS.
Saxena, A. et al. (2010), “Metrics for Offline Evaluation of Prognostic Performance”, International Journal of Prognostics and Health Management, No. 1, pp. 1–20.
Schwabacher, M.; Goebel, K. (2007), “A survey of artificial intelligence for prognostics”, Association for the Advancement of Artificial Intelligence AAAI Fall Symposium 2007, pp. 107–14.
Shanks, E. et al. (2003), “Deepwater BOP control systems-a look at reliability issues”, Offshore Technology Conference, pp. 1–10. doi: 10.4043/15194-MS.
Sharma, R. K.; Sharma, P. (2010), “System failure behavior and maintenance decision making using, RCA, FMEA and FM”, Journal of Quality in Maintenance Engineering, Vol. 16, No. 1, pp. 64–88. doi: 10.1108/13552511011030336.
Shin, J. H.; Jun, H.B. (2015), “On condition-based maintenance policy”, Journal of Computational Design and Engineering, Vol. 2, No. 2, pp. 119–27. doi: 10.1016/j.jcde.2014.12.006.
Snooke, N.; Price, C. (2012), “Automated FMEA based diagnostic symptom generation”, Advanced Engineering Informatics, Vol. 26, No. 4, pp. 870–88. doi: 10.1016/j.aei.2012.07.001.
Stamatis, D. H. (1995), Failure mode and effect analysis: FMEA from theory to execution, ASQC Press, New York.
Tam, A. S. B.; Gordon, I. (2009), “Clarification of failure terminology by examining a generic failure development process”, International Journal of Engineering Business Management, Vol.1, No. 1, pp. 33–36. doi: 10.5772/6782.
Tang, Y. et al. (2015), “Study on stress distribution of a subsea Ram BOP body based on simulation and experiment”, Engineering Failure Analysis, No. 50, pp. 39–50. doi: 10.1016/j.engfailanal.2014.12.018.
Tian, Z. et al. (2011), “Condition based maintenance optimization for wind power generation ystems under continuous monitoring”, Renewable Energy, Vol. 36, No. 5, pp. 1502–09. doi: 10.1016/j.renene.2010.10.028.
Tobon-mejia, D. et al. (2012), “A data-driven failure prognostics method based on mixture of gaussians hidden markov models To cite this version: A Data-Driven Failure Prognostics Method based on Mixture of Gaussians Hidden Markov Models”, IEEE Transactions On Reliability, Vol. 61, No.2, pp. 491–503.
Tsang, A. H. C. (1995), “Condition-based maintenance: tools and decision making”, Journal of Quality in Maintenance Engineering, Vol.1, No. 3, pp. 3–17. doi: 10.1108/13552519510096350.
Tuchband, B. et al. (2007), “Technology Assessment of Sensor Systems for Prognostics and Health Monitoring. In Proceedings of IMAPS on Military, Aerospace, Space and Homeland Security: Packaging Issues and Applications (MASH)”.
US Chemical Safety Hazard and Investigation Board (2010), “US Chemical Safety and Hazard Investigation Board Investigation Report Volume 1”, Explosion and Fire at the Macondo Well, Vol.1, (Investigation Report), pp. 1–37.
US DoD 4151.22-M (2011), “Reliability Centered Maintenance - RCM”, No. 4630, pp. 1–77.
Vachtsevanos, G. et al. (2006), Intelligent Fault Diagnosis and Prognosis for Engineering Systems. doi: 10.1002/9780470117842.
Vichare, N. M.; Pecht, M. G. (2006), “Prognostics and health management of electronics”, IEEE Transactions on Components and Packaging Technologies, Vol. 29, No. 1, pp. 222–29. doi: 10.1109/TCAPT.2006.870387.
Xiao, N. et al. (2011), “Multiple failure modes analysis and weighted risk priority number evaluation in FMEA”, Engineering Failure Analysis, Vol. 18, No. 4, pp. 1162–70. doi: 10.1016/j.engfailanal.2011.02.004.
Yam, R. C. M. et al. (2001), “Intelligent predictive decision support system for condition-based maintenance”, International Journal of Advanced Manufacturing Technology, Vol. 17, No. 5, pp. 383–91. doi: 10.1007/s001700170173.
Received: Jul 12, 2017
Approved: Jan 12, 2018
DOI: 10.14488/BJOPM. 2018.v15. n1. a8
How to cite: Martins, F. B.; Colombo, D.; Matos, B. A. (2018), “Applying CBM and PHM concepts with reliability approach for Blowout Preventer (BOP): A literature review”, Brazilian Journal of Operations & Production Management, Vol. 15, No. 1, pp. 78-95, available from: https://bjopm.emnuvens.com.br/bjopm/article/view/417 (access year month day).